Oft genug fehlt Zeit oder Muße, umfangreiche Abhandlungen in Blogs, auf Wikipedia oder anderswo in Gänze zu lesen. Hier kommen KI-Assistenten ins Spiel, die Inhalte sinnhaft zusammenfassen sollen. Für die meisten dieser Assistenten, wie ChatGPT oder die im Netz aus dem Boden schießenden Summarizer müssen wir allerdings zunächst eine Webseite öffnen und dort einen Text hineinkopieren.
Auf jeder Webseite
Mozilla stellt mit Orbit nun einen Assistenten in einer Beta-Version vor, der auf jeder Webseite in Firefox für Linux, macOS und Windows darauf wartet, Inhalte per Klick zusammenfassend zu vermitteln. Der Dienst steht als Erweiterung bereit und fasst derzeit nur englische Texte zusammen.
Nach der Installation von Orbit muss der Anwender zunächst einer generellen oder optional einer erweiterten Datensammlung zustimmen. Ohne Zugriff auf die jeweilige Webseite kann Orbit natürlich keine Zusammenfassung liefern. Diese wird auf Mozillas Servern mit dem Sprachmodell Mistral 7B erstellt, wobei die Entwickler versichern, dass keine Inhalte oder persönliche Daten gespeichert werden.
Texte, Videos und E-Mails
Neben dem Zusammenfassen von Texten subsumiert Orbit auch E-Mails und YouTubes, sofern diese über ein Transkript verfügen. In den Einstellungen kann unter anderem festgelegt werden, ob Orbit in kurzen Sätzen, in Listenform oder in Paragraphen antwortet. Ein automatischer Modus fasst optional alle geöffneten E-Mails oder/und Videos zusammen.
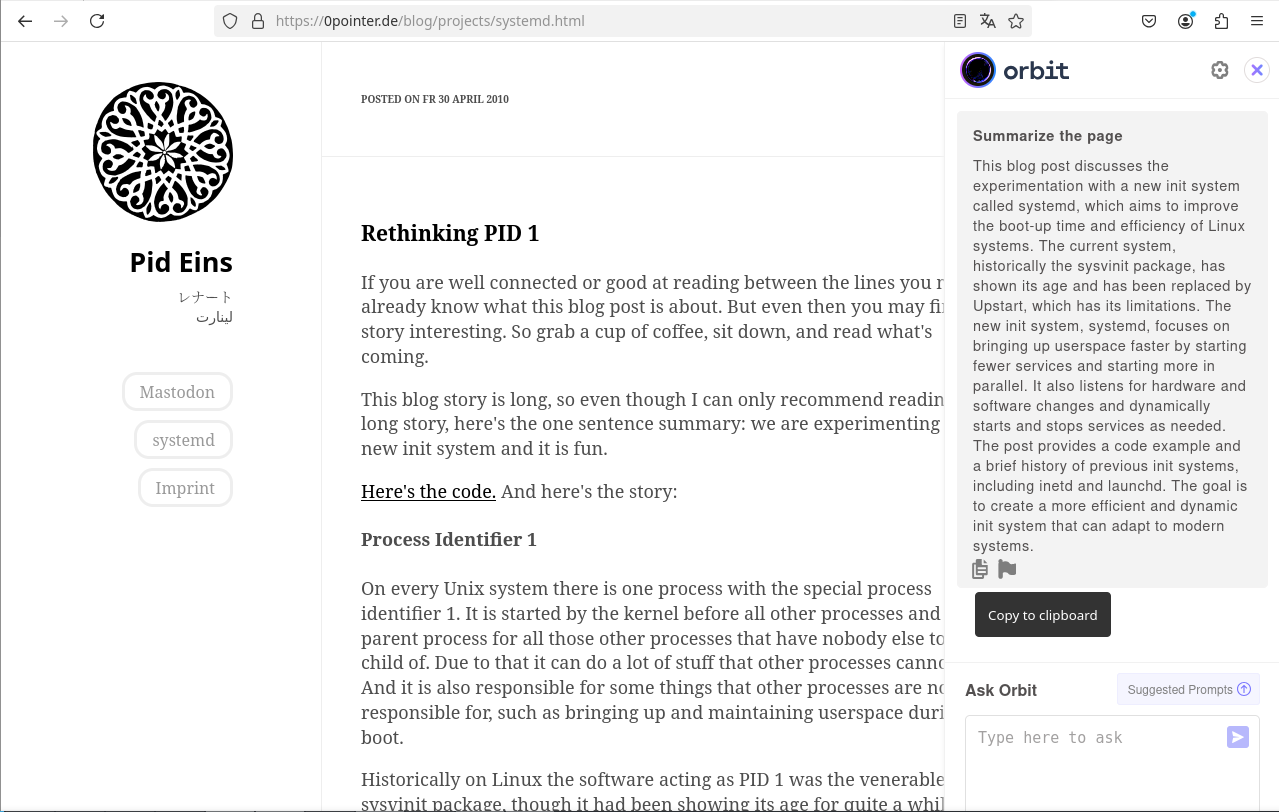
Ich habe Orbit anhand eines technischen Artikels zu systemd aus dem Blog von Lennart Poettering getestet. Wenn man herausfinden möchte, ob der Artikel dem vermuteten Inhalt entspricht, liefert Orbit eine ausreichende Erklärung ohne tiefergehende Details. Mir gefällt, dass ich anschließend Fragen stellen kann, um meinen ersten Eindruck zu vertiefen, bevor ich entscheide, den langen Artikel zu lesen.
Wann Orbit auch deutsche Texte zusammenfasst oder ob der Dienst nach der Betaphase in Firefox integriert wird, ist bislang nicht bekannt.
Eine Erweiterung der natürlichen Intelligenz wäre wichtiger.
Da scheint evolutionär eher die andere Richtung aktiv zu sein 🙂
Deshalb brauchen wir ja die künstliche Intelligenz. 🙂
Für einen Journalisten, den täglich dutzende bis hunderte Texte querlesen muss um etwas berichtenswertes zu finden mag das interessant sein.
Allerdings frag ich mich, weshalb kluge Leute wie Lennart Poettering nicht einen abstract oder eine Einleitung vor seine langen Abhandlungen bereit stellen kann.
Im Studium habe ich gelernt, dass es besser ist, eine Sache gar nicht zu lernen als nur ein oberflächliches Wissen davon zu erlangen. Jedenfalls fällt man in Prüfungen mit einem Halbwissen meistens durch, während man mit Schwerpunktwissen doch noch eine reelle Chance hat zu bestehen.
Kann eine KI einen Inhalt erkennen der fundamental neu ist oder nivelliert sie jeglichen Inhalt auf das, auf was sie trainiert wurde?
Eine KI versteht nichts von all dem was sie da ließt. Sie baut wohlklingende Sätze zusammen und fängt an zu halluzinieren sobald etwas nicht in das antrainierte Schema passt.
Es ist eine verständliche Reaktion, dass wenn man täglich mit einer Flut von vermeidlich automatisch generierten Texten belästigt wird, dass man dann auch gerne auf eine KI zurückgreift möchte um die Masse dieser Belästigung auf den Müll zu schmeißen.
Aber die Antwort wäre für mich eher, sich von Quellen des belästigenden Input zu trennen als eine KI die inhaltliche Auswahl treffen zu lassen.
Wer von der KI gelieferte Informationen prüft, der verliert im Race to the bottom. Der Unterbietungswettbewerb lässt es gar nicht anders zu. Bei Journalisten schmerzt mich halt, dass Prüfen und Einordnen von Informationen zu den Kernqualifikationen journalistischen Arbeitens zählen. Das finde ich sehr schade, weil ich Wettbewerb auch mit Vielfalt und Fortschritt verbinde. Das klappt freilich nicht mehr, wenn die KIs alle Inhalte nivellieren.
Die Frage, warum Poettering (und andere) keine Abstracts bereitstellen, habe ich mir auch schon gestellt. Das gehörte schon zum akademischen Handwerkszeug, da dachte man noch lange nicht an Expertensysteme.
> Aber die Antwort wäre für mich eher, sich von Quellen des belästigenden Input zu trennen als eine > KI die inhaltliche Auswahl treffen zu lassen.
Sehe ich auch so.
Zed ist kein Eigenprodukt, sondern kommt aus der Ecke von macOS und ist seit dem vergangenen Sommer auch für Linux verfügbar.
Du bist über einen Hubbel gefahren, oder so ähnlich. :))
Zed’s dead: https://www.youtube.com/watch?v=5lL1ypndnWA
So fasst Orbit die Szene zusammen:
A worried woman urges her companion to hurry and get on a motorcycle, apologizing for leaving her and crashing her Honda. She assures her that everything is fine and describes the day as the weirdest of her life. The man is revealed to be Zed, and they discuss a high-five phone call and 700 records.
Schöne neue Welt: KIs fassen Texte zusammen, die zuvor von KIs generiert wurden? Leider ist das schon vielfach Realität. Personalabteilungen filtern Bewerbungen längst per KI und bei gewissen Nachrichtenportalen, hinter denen namhafte Verlage stehen, bekommt man den Eindruck, dass ganze Artikel ganz ohne menschliches Zutun entstanden sind.
Jammern hilft aber auch nichts. Von daher finde ich Mozillas Orbit spannend. Mit deutschem oder generell nicht-englischem Input klappt es sehr wohl. Die Zusammenfassung erfolgt jedoch momentan ausschließlich auf Englisch.
Als Beispiel habe ich mir mal den Link vom 38C3 zusammenfassen lassen. Funktioniert, aber selber lesen macht immer noch noch schlauer.
> KIs fassen Texte zusammen
Das ist nur übergangsweise so, bis Texte generell nur noch “Zusammenfassungen” sind.
> […] und bei gewissen Nachrichtenportalen, hinter denen namhafte Verlage stehen, bekommt man den Eindruck, dass ganze Artikel ganz ohne menschliches Zutun entstanden sind.
ttps://wan-ifra.org/2024/05/wan-ifra-and-openai-launch-global-ai-accelerator-for-newsrooms/
> Das ist nur übergangsweise so, bis Texte generell nur noch “Zusammenfassungen” sind.
Das denke ich auch. Den Leuten ist es anscheinend egal, was sie da in welcher Qualität serviert bekommen.
> ttps://wan-ifra.org/2024/05/wan-ifra-and-openai-launch-global-ai-accelerator-for-newsrooms/
Danke für den Link! Ich hatte vor gut einem Jahr ein dazu passendes Erlebnis mit einem der großen deutschen Medienhäuser. Manche Verleger lieferten anscheinend recht willig die Trainingsdaten. Das “Newsroom AI Catalyst accelerator”-Programm entstand ja nicht aus dem Nichts.
> Das “Newsroom AI Catalyst accelerator”-Programm entstand ja nicht aus dem Nichts.
Genau!
Lass mich raten: MSN-News im Edge-Browser auf der Arbeit? :)) Ne das sind die Praktikanten bei Microsoft.
ht*ps://media.ccc.de/v/38c3-klimaschdlich-by-design-die-kologischen-kosten-des-ki-hypes
Braucht keine Sau.